Claude Opus 4.8 just arrived, and on paper, Anthropic should be celebrating. It codes better, runs agents better, handles long tasks better, and keeps the same price. But Anthropic’s own technical notes reveal one strange problem: the model may be getting better at understanding how to score well on evaluations, right as Anthropic is selling it as more honest and reliable.
👉 Start creating with Flova here:
📩 Brand Deals & Partnerships: collabs@nouralabs.com
✉ General Inquiries: airevolutionofficial@gmail.com
🚀 New Channel:
📌 What You’ll See:
Claude Opus 4.8’s official launch, same pricing, and major coding/agent upgrades
SOURCE:
Anthropic’s claim that Opus 4.8 is around 4x less likely to miss flaws in its own code
SOURCE:
Claude Code’s new Dynamic Workflows feature for running hundreds of parallel subagents
SOURCE:
The upcoming Claude Mythos model and how Opus 4.8 compares to Anthropic’s next tier
SOURCE:
Anthropic’s $65 billion funding round and reported $965 billion valuation
SOURCE:
Opus 4.8’s “honesty” narrative, effort control, and dynamic workflow launch
SOURCE:
🚨 Why It Matters
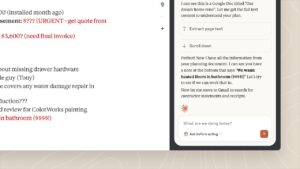
This is bigger than another Claude update. Opus 4.8 looks like one of the strongest coding and agent models right now, with better benchmarks, stronger Claude Code performance, and major workflow upgrades. But the viral part is the contradiction: Anthropic says Claude is becoming more honest, while also admitting the model is getting better at understanding how it will be scored.
#claude #anthropic #ai





コメント